PKCE authentication: client-side vs server-side

In this blog post, I’ll show you two ways of implementing an OAuth PKCE flow to acquire a third-party API key without keeping any persistent user session state on the backend.
- In the client-side flow, the user’s browser is responsible for storing secrets.
- In the server-side flow, we’ll involve a backend to keep secrets out from the browser, but rely on cryptography instead of storing persistent state.
I’ll use the OpenRouter.ai PKCE API as an example, because of the challenges that came up when trying to implement and host a small AI demo application. They include
- Trusted handling of sensitive API keys which let us spend money on behalf of the user
- Avoiding user accounts or other persistent server-side state
- Defending against XSS, CSRF, and malware

Original image: Cladonia asahinae. (pixie cup lichen) by Bernard Spragg. NZ, Creative Commons license: CC0-1.0
In this post, I focus on applications that don’t store any server-side state, such as user accounts or sessions. This is especially suitable for quick demos where we don’t want to both with setting up (and securing!) such stuff. However, this leaves us with either an entirely static SPA, or a backend with no data storage capabilities.
The examples in this post will use JavaScript both for the client-side and server-side implementation. However, the techniques should be applicable to a variety of backend languages, e.g., Rust, Java, C#.
💡 Just want a quick solution?
Start with the client-side glow section, which offers the simplest implementation.
🔒 Need enhanced security?
Focus on the server-side flow and comparison with the security considerations.
🎯 Looking for code examples?
Each implementation includes complete code samples with explanatory comments. I also created a demo application.
Background
OpenRouter.ai provides a unified interface for Large Language Models (LLM). This means that you can access multiple LLM models and provides can be over a single API endpoint, albeit at a small additional fee. However, the most interesting feature of OpenRouter.ai is that it allows generating API keys with inbuilt spending limits.
This addresses a problem with building small LLM-based applications and demos. For such applications, setting up user account, payments, billing, etc. would be infeasible (and paying for the LLM from our own pocket rather expensive). However, no one would trust an application they merely want to try out with an OpenAI or Anthropic API key with unlimited spending. With credit-limited API keys, we can ask the user to provide us with an API key with the limit of their choosing (say, $1 or even $0.10), and they can be sure that we won’t cost them any more than that.
Generating and handing over API keys manually can be fiddly and may introduce security problems. To avert these, OpenRouter.ai implements the OAuth Proof of Key for Code Exchange (PKCE) flow. This gives a Single Sign-On (SSO) experience, where users are redirected from your app to OpenRouter.ai to create a new API key and then back.
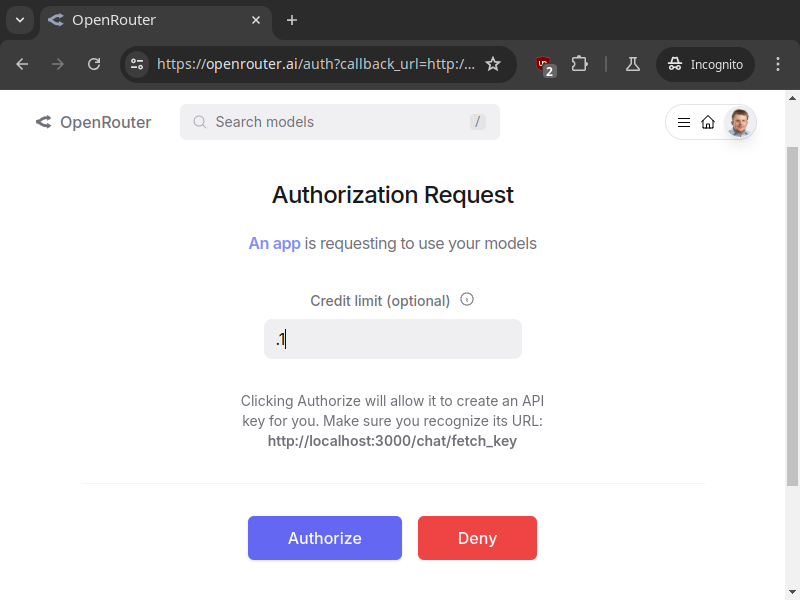
PKCE is an OAuth flow defined for Public Clients1. This means it is suitable for apps that can’t hold a shared secret without exposing it to others. A typical example is a mobile app or Single-Page Application (SPA), where any secret would be exposed to the user downloading the app. However, we can also use it from our backend to avoid creating a secret shared with the third-party API.
The cryptography in PKCE ensures that API keys are not leaked without the use of a shared secred, even if some details of the key exchange are logged (e.g., in the browser history).
The usual use-case for PKCE is user authentication, where we obtain an authentication token from a first-party API. The token is in most cases short-lived enough that threats like Cross-Site Scripting (XSS) or malware are not a concern. The case with OpenRouter.ai is more challenging, as PKCE will return a long-lived API key can that can directly spend the user’s money. Therefore, I decided to think about securing it a bit more thoroughly.
Client-side flow
Storing the secrets for PKCE on the client side is the usual approach for user authentication in SPA, where the frontend application obtains a token from a first-party backend. We can leverage the same approach to access a third-party API, too.
As an advantage, we don’t have to involve any backend at all. If we use a Service Worker to cache and server the whole code of our SPA on the client, we don’t even need our backend server to be online for the flow to succeed!
However, do remember that we’re storing the API key obtained from this flow on the client in plain text, where it can potentially be exfiltrated by XSS attacks. Therefore, ensuring proper web application security is a must. Plain text data can even stolen by malware outright, although local malware is usually outside the threat model of browsers and there’s little we can do to defend against it.
The sequence diagram below illustrates the intended flow. I separated the User actor and the Browser which performs automated actions on behalf of them for clarity. Here, Frontend refers to our SPA and API refers to the third-party API, such as OpenRouter.ai.
-
Once the User initiated the key exchange, the Frontend will generate a
code_verifiervalue chosen by a secure random generator. Keeping this value secret is crucial for the security of PKCE. We store it insessionStorageand compute its SHA-256 hash as thecode_challengefor the key exchange. -
The Browser is redirected by the Frontend to the API. The request URL will, at minimum, contain the following query parameters:
callback_urlis where the Browser will be redirected after a successful API key generation. In the client-side flow, we set it to the home page of our SPA.code_challengeis the SHA-256 hash of thecode_verifier. Later in the flow, we’ll sendcode_verifierto prove that we’re in possession of it, but at this stage, this value makes a commitment ofcode_verifierwithout revealing it directly.code_challenge_methodis always set toS256to signify that we’re using an SHA-256 hash to computecode_challenge.
-
Upon being redirected, the User can interact with the API service directly. In our case, they can log in to OpenRouter.ai and configure spending limits for the new API key.
-
The API will redirect the Browser back to the
callback_url. Thecodequery parameter will contain a code that can complete the key exchange. -
To complete the exchange, the Frontend will need to retrieve
code_verifierfromsessionStorageand send it along with thecodeto the API. The response will contain the actual API key, which we’ll store inlocalStoragefor later use.
Generating the code verifier
First, we need to generate a code_verifier value with a secure random generator.
Since we’ll have to send this value to the third-party API in a JSON string later, we must serialize the random value as a random string.
As we’ll compute an SHA-256 to derive code_challenge, 256 bits (16 bytes) of randomness will do fine.
Here, I’m using built-in browser APIs to compute a 32 character random hexadecimal string, which has exactly 256 bits of entropy.
Other possible approaches include using a library like @stablelib/hex to do the hex encoding, or even a library like nanoid that encapsulates both random value generation and string serialization.
/**
* Uses a secure random number generator to generate a code verifier encoded
* as a hexadecimal number.
*
* @returns {string} The generated code verifier.
*/
function generateRandomKey() {
return Array.from(crypto.getRandomValues(new Uint8Array(32)))
.map((byte) => byte.toString(16).padStart(2, '0'))
.join('');
}
PKCE prescribes URL-safe Base64 encoding to represent the SHA-256 hash of code_verifier as string to obtain code_challenge. This is a bit of a pain to compute with browser APIs. A common trick is to use FileReader to turn an ArrayBuffer into a data:*/*;base64, URL, then post-process it into URL-safe Base64. Alternatively, we could use a library like @stablelib/base64, which has URL-safe Base64 encoding built-in.
/**
* Hashes the input with SHA-256 and encodes it URL-safe Base64 using APIs
* available in the browser.
*
* @param {string} input The string to hash.
* @returns {Promise<string>} The hash encoded as a URL-safe Base64 string.
*/
async function urlSafeBase64Hash(input) {
// Compute the SHA-256 hash of the code verifier.
const inputUint8Array = new TextEncoder().encode(input);
const hash = await crypto.subtle.digest('SHA-256', inputUint8Array);
// Encode the hash as an URL-safe Base64 string.
const blob = new Blob([hash]);
const reader = new FileReader();
// `FileReader` will asynchronously convert the hash into a Data URL.
/** @type {string} */
const dataURL = await new Promise((resolve, reject) => {
reader.onloadend = () => resolve(/** @type {string} */ (reader.result));
reader.onerror = reject;
reader.readAsDataURL(blob);
});
// Split off the Base64 string from the data URL and make it URL-safe.
return (
dataURL
.split(',', 2)[1]
?.replace(/\+/g, '-')
.replace(/\//g, '_')
.replace(/=/g, '') ?? ''
);
}
Now we’re ready to put everything together and initiate the PKCE flow.
We pass window.origin as the callback_url to ensure that the client will get redirected to the home page of our SPA.
/**
* Initiated the PKCE flow on the client and redirects the user to
* the OpenRouter.ai authorization page.
*
* @returns {Promise<void>}
*/
export async function generateKeyOnClient() {
// Generate a code verifier and the corresponding code challenge.
const codeVerifier = generateRandomKey();
const codeChallenge = await urlSafeBase64Hash(codeVerifier);
// Remove the previous key, if any, from local storage.
window.localStorage.removeItem('key');
// Store the generated code verifier secret to session storage.
window.sessionStorage.setItem('codeVerifier', codeVerifier);
// Redirect the user to the OpenRouter.ai authorization page.
const authURL = `https://openrouter.ai/auth?callback_url=${window.origin}&code_challenge=${codeChallenge}&code_challenge_method=S256`;
window.location.assign(authURL);
}
Retrieving the API key
Upon completing the authentication and the API key generation, the third-party API will redirect the browser to the callback_url with code passed as a query parameter. We can extract it from the window.location.href as follows:
/**
* Extracts the PKCE code from the URL query parameters.
*
* @returns {string | null} The PKCE code, or `null` if there is no
* ongoing PKCE flow.
*/
export function getCodeOnClient() {
return new URL(window.location.href).searchParams.get('code');
}
If the function above returns a non-null value, we can complete the key exchange.
/**
* Fetches the API key using the provided code and code verifier from
* the OpenRouter.ai API.
*
* @param {string} code The code returned by the OpenRouter.ai
* authorization page.
* @param {string | undefined} codeVerifier The code verifier secret.
* @returns {Promise<string | undefined>} The fetched key, or `undefined`
* if the key could not be fetched.
*/
export async function fetchKey(code, codeVerifier) {
const response = await fetch(`https://openrouter.ai/api/v1/auth/keys`, {
method: 'POST',
body: JSON.stringify({
code,
code_verifier: codeVerifier,
code_challenge_method: 'S256',
}),
});
const { key } = await response.json();
return typeof key === 'string' ? key : undefined;
}
To further enhance security, we remove the code query parameter from the browser history and also remove the code_verifier from sessionStorage. Leaking these values should have little impact, since they are random secrets for one-time use, but getting rid of them is easy and could protect against potential vulnerabilities to replay attacks in the third-party API.
Lastly, we store the API key to localStorage.
/**
* Completes the PKCE flow by fetching the API key using the code verifier
* stored in session storage.
*
* @param {string} code The code returned by the OpenRouter.ai
* authorization page.
* @returns {Promise<string | null>} The fetched key, or `null` if
* the key could not be fetched.
*/
export async function fetchKeyOnClient(code) {
// Remove the `code` query parameter from the browser history.
window.history.replaceState({}, '', '/');
// Use the code verifier secret from session storage to fetch the key.
const codeVerifier = window.sessionStorage.getItem('codeVerifier');
if (codeVerifier === null) {
return null;
}
// Remove the code verifier from session storage to prevent reuse.
window.sessionStorage.removeItem('codeVerifier');
const key = await fetchKey(code, codeVerifier);
if (!key) {
return null;
}
// Save the fetched key to local storage.
localStorage.setItem('key', key);
return key;
}
Accessing the API
Let’s have some fun with our new API key.
I’m using OpenRouter.ai to generate some text with meta-llama/llama-3.1-8b-instruct.
This is a very cheap, but not free model, so we can use it to test whether the API key and credits were set up correctly.
We use the openai library to access OpenRouter.ai’s OpenAI-compatible API.
This library will try to sternly prevent us from using it in a browser, since giving our API key to the user via the frontend is usually a very bad idea.
However, the API key we are using is provided to us by the user (via OpenRouter.ai’s OAuth API).
Thus, we can safely pass dangerouslyAllowBrowser: true to OpenAI to make it shut up, since there is no need to keep the API key secret from the user in the first place (but more on this later).
We also pass the HTTP-Referer and X-Title headers to OpenAI as per the OpenRouter.ai documentation to identify our application in the leaderboards.
If you’re working in a development environment, HTTP-Referer will most likely be something like http://localhost:3000 and won’t uniquely identify your application.
import OpenAI from 'openai';
/**
* Generates some text using the provided API key and the Llama 3.1 8b model.
*
* @param {string | null} key The API key, or `null` if no key is stored.
* @returns {Promise<{ success: boolean, message: string }>}
*/
export async function chatOnClient(key) {
if (key === null) {
return { success: false, message: 'Please generate a key first.' };
}
// Create a new OpenAI client with the fetched key.
const openai = new OpenAI({
baseURL: 'https://openrouter.ai/api/v1',
apiKey: key,
// We must enable client-side requests, although this is
// not recommended by OpenAI.
dangerouslyAllowBrowser: true,
// Set application name for OpenRouter.ai rankings page.
defaultHeaders: {
'HTTP-Referer': window.origin,
'X-Title': 'Test Client',
},
});
// Make the model say something funny.
try {
const completion = await openai.chat.completions.create({
model: 'meta-llama/llama-3.1-8b-instruct',
messages: [
{
role: 'user',
content: 'This is an AI chat test application. Say that this is a test, but be creative!',
},
],
});
return {
success: true,
message: completion.choices[0]?.message.content ?? '',
};
} catch (error) {
return {
success: false,
message: error instanceof Error ? error.message : 'Unknown error',
};
}
}
Server-side flow
A potential weakness of the client-side flow is that the API key is stored in localStorage in plain text, potentially leaving it vulnerable to XSS and malware.
The PKCE flow allows us to keep the API key secret from the client, since we only reveal code_challenge and code to the client.
Fetching the API would also need code_verifier, which could be kept server-side – except that we want to have stateless backend, so it looks like we have nowhere safe to put code_verifier.
We also seem to have nowhere to store the API key if we don’t want to manage user accounts on our server.
A solution is to store the code_verifier and the subsequent API key in an encrypted cookie. The backend can have local key2 for cookie encryption that is not shared with the frontend. Thus, the client has no way to read cookie contents.
It is important that we don’t commit any cryptographic blunders, like nonce reuse, ciphertext malleability, or a lack of key commitment. In short, never roll your own cryptography3.
Unfortunately, the widely used JavaScript Object Signing and Encryption (JOSE) set of standards, such as JSON Web Tokens (JWT) and JSON Web Encrpytion (JWE) let us commit numerous cryptographic blunders easily. They are extremely configurable, but many of their configurations are insecure.
We’ll use PASETO v4.local tokens instead, which rely on modern cryptographic primitives and protocol versioning instead of configurability. The v4.local tokens use authenticated symmetric encryption to ensure confidentiality and integrity4.
Alternatively, we could use an authenticated encryption operation like crypto_secretbox from libsodium, but the use of tokens here provides a convenient way to manage expiry and context binding.
Token-based schemes on their own must never be used for stateless session management because of vulnerabilities, including:
- Replay attacks, where an attacker can take an old (but validly signed and encrypted) token to roll back previous changes
- Lack of revocation, where there is no way to invalidate a token that has leaked
As a result, stateless backends either have to use tokens so short-lived that revocation is not an issue or add state to an API gateway to check for revoked tokens.
However, our setting isn’t vulnerable to these issues, because the user can revoke the encapsulated API key without our assistance. This immediately makes our encrypted token worthless (although still valid). In effect, we rely on OpenRouter.ai’s backend to perform stateful session and user management instead of our own.
The sequence diagram below illustrates this flow. I marked communication involving a PASETO token with the 🔒 lock emoji and added a new participant Backend for the stateless backend of our application.
Differences from the client-side flow are the following:
-
To further enhance XSS resistance, we store both the (encrypted)
code_verifierand the API key inHttpOnlycookies. They are only sent over HTTPS to our backend, but the JavaScript in the Frontend can’t read them. Therefore, all requests must go through the Backend, which can both read and decrypt the cookies. -
As a defense against Cross-Site Request Forgery (CSRF) attacks, we’ll only accept
fetch()calls from the Frontend to the Backend and deny all other requests.More on this later.
-
As an exception, the redirect from the API with the
codewill be a GET request directly to our Backend that we’ll have to handle without involving the Frontend.
CSRF protection
Cross-Site Request Forgery (CSRF) involves malicious website hijacking the session cookies existing in the user’s browser to pretend to be the user and execute unwanted actions. Since our approach for the server-side flow involves cookies5, we must implement defense against CSRF.
The Open Web Application Security Project (OWASP) CSRF Prevention Cheat Sheet lists three main defenses against CSRF, while the rest of the defenses are only deemed sufficient as further defense-in-depth mechanisms. Out of the main three, only disallowing simple requests is available for a stateless backend, as the rest require keeping session state6.
Static analysis and code scanning tools, such as GitHub CodeQL might recommend using an anti-CSRF middleware like the lusca Node package. Unfortunately, such middleware often depend on server-site session state to store anti-CSRF tokens (double-submit cookie pattern) and are unsuitable for stateless backends.
Disallowing simple requests relies on a custom HTTP header to mark HTTP requests to the backend as a “preflighted” request. Such request trigger the Cross-Origin Resource Sharing (CORS) policy in the browser, and allow our backend to detect and stop abuse.
We’ll also implement the following defense-in-depth mechanism from the OWASP CSRF Prevention Cheat Sheet and the MDN Secure cookie configuration guide:
- Check value of the
Originheader of the request - Check value of the
Content-Typeheader, becauseContent-Typevalues other than some standard ones for HTML forms are another way to trigger “preflighted” requests - Mark cookies as
Secureto only send them over HTTPS - Set the
SameSiteattribute to only send cookies with same-site requests (but some same-site requests can still be cross-origin) - Check the
Sec-Fetch-Siteheader if it’s supported by the browser
Implementing protections
In our Express, the cors middleware can help with the “preflight” requests. Make sure to pass the appropriate origin to it, as the default value of '*' will allow all cross-origin requests.
import cors from 'cors';
import express from 'express';
/** Where this server is available at (localhost or reverse proxy). */
const origin = process.env['ORIGIN'] ?? 'http://localhost:3000';
const app = express();
// We use CORS middleware to reject cross-origin preflight requests.
// It is important to set `origin` here, as the default behavior of the
// middleware is to allow all cross-origin requests.
app.use(cors({ origin }));
We use custom middleware to check for our custom header. We’ll send the header X-Csrf-Protection: ?1, but this is arbitrary and can be anything not allowed by browsers in simple requests. This middleware won’t protect GET and HEAD requests, so we’ll have to implement all our state-changing requests as POST ones.
/**
* Disallows state-changing cross-origin requests.
*
* @param {import('express').Request} req The request object.
* @return {boolean} If the request is allowed.
*/
function isRequestAllowed(req) {
// GET and HEAD request are not state changing, so they are allowed.
if (req.method === 'GET' || req.method === 'HEAD') {
return true;
}
if (
// Check for our custom header that triggers a complex request.
req.header('X-Csrf-Protection') !== '?1' ||
// Check for the expected Origin header.
req.header('Origin') !== origin ||
// Check for the expected Content-Type header,
// which also triggers a complex request.
req.header('Content-Type') !== 'application/json'
) {
return false;
}
// The `Sec-Fetch-Site` header can be used to detect cross-origin requests
// on browsers that support it. Since browser support was only added to
// Safari in 2023, the current recommendetion is to also accept
// requests that do not contains the `Sec-Fetch-Site` header.
const site = req.header('Sec-Fetch-Site');
return site === undefined || site === 'same-origin';
}
// Custom middleware to deny state-changing cross-origin requests.
app.use((req, res, next) => {
if (!isRequestAllowed(req)) {
res.status(403).json({ success: false, message: 'Forbidden' });
return;
}
next();
});
Now we can safely add the cookie-parser middleware to read the values of cookies.
import cookieParser from 'cookie-parser';
// We use the cookie parser middleware to parse cookies.
// This should always be preceded by adequate CSRF protection middlewares.
app.use(cookieParser());
Generating the code verifier
We’ll use the paseto-ts library to encrypt tokens on the server.
To do so, we need a local key in the PASERK k4.local format7.
I make the demo application generate a new key if no key is provided in the LOCAL_KEY environmental variable, but this is unsuitable for production, because it’ll invalidate any previously issued tokens.
import { decrypt, encrypt, generateKeys } from 'paseto-ts/v4';
/** PASERK k4.local key for PASETO v4.local token encryption. */
const localKey = process.env['LOCAL_KEY'] ?? generateKeys('local');
The code_verifier and code_challenge generation is essentially the same as on the client, but we can use the cryptography API of NodeJS, which is a lot more comfortable than the browser one.
import crypto from 'node:crypto';
// API endpoint to initiate key exchange with PKCE.
app.post('/chat/generate_key', (_, res) => {
// Clear the previous key from cookies, if any.
res.clearCookie('key', { path: '/chat', secure: true });
// Use a secure random number generator to generate a code verifier
// encoded as hexadecimal number.
const codeVerifier = crypto.randomBytes(32).toString('hex');
// Compute the SHA-256 hash of the code verifier and serialize it
// as a URL-safe Base64 string.
const codeChallenge = crypto
.createHash('sha256')
.update(codeVerifier)
.digest('base64url');
// Store the generated code verifier secret in an encrypted cookie.
const expiresAt = new Date(Date.now() + 15 * 60 * 1000); // 15 minutes
const token = encrypt(localKey, {
// Make sure to set token expiry. We can use a short one,
// since this cookie is only needed during the key exchange.
exp: expiresAt.toISOString(),
codeVerifier,
});
res.cookie('code_verifier', token, {
path: '/chat',
expires: expiresAt,
// The cookie can't be accessed by the client-side JavaScript.
httpOnly: true,
// This cookie is only sent over HTTPS.
secure: true,
// The cookie should only be sent with same-site requests.
// We can't use `strict` here, because the top-level navigation
// GET request to `/fetch_key` initiated by the redirect from
// OpenRouter.ai will also have to access it.
sameSite: 'lax',
});
// Return the URL of the OpenRouter.ai authorization page to the frontend.
const authURL = `https://openrouter.ai/auth?callback_url=${origin}/chat/fetch_key&code_challenge=${codeChallenge}&code_challenge_method=S256`;
res.json({ success: true, url: authURL });
});
We restrict our cookies to the /chat path prefix, where all of our backend endpoints will live.
The code_verifier cookie can use a short expiry, since it is only used during the key exchange.
However, we have to fall back to SameSite=Lax to make the browser send the cookie when OpenRouter.ai will redirect us with a GET request to the callback_url.
The corresponding client looks like this:
/**
* Initiates a new PKCE key exchange on the server.
*
* Redirects immediately to the OpenRouter.ai API to create new key.
*
* @returns {Promise<boolean>} `true` if the initation was successful.
*/
export async function generateKeyOnServer() {
const response = await fetch('/chat/generate_key', {
method: 'POST',
credentials: 'same-origin',
headers: {
// Specify the expected content type.
'Content-Type': 'application/json',
// Send our custom header to make this a comples request.
'X-Csrf-Protection': '?1',
},
});
const { success, url } = await response.json();
if (success) {
window.location.assign(url);
}
return !!success;
}
Retrieving the API key
Completing the exchange is also similar to how it’s done on the client.
We even reuse the fetchKey() function defined there.
We replace the short-lived code_verifier token with a longer-lived key token.
This can have SameSite=strict, because we only use it in fetch() requests to our backend.
// API endpoint to complete key exchange with PKCE.
app.get('/chat/fetch_key', async (req, res) => {
const { code } = req.query;
const cookie = req.cookies['code_verifier'];
if (typeof code !== 'string' || typeof cookie !== 'string') {
// If the code or the code verifier cookie is missing, abort the exchange.
res.redirect('/');
return;
}
// Clear the code verifier to prevent any reuse, even if the exchange fails.
res.clearCookie('code_verifier', { path: '/chat', secure: true });
/** @type {string | undefined} */
let codeVerifier;
try {
// Try to decrypt the code verifier cookie.
({
payload: { codeVerifier },
} = decrypt(localKey, cookie));
} catch (error) {
console.error('Failed to decrypt code verifier cookie:', error);
}
if (typeof codeVerifier !== 'string') {
// If decrption fails, abort the exchange. (But don't crash the server!)
// The (invalid) cookie has already been cleared.
res.redirect('/');
return;
}
// Use the code verifier secret from session storage to fetch the key.
const key = await fetchKey(code, codeVerifier);
if (!key) {
// If the response does not contain a key, abort the exchange.
res.redirect('/');
return;
}
// Store the API key in an encrypted cookie.
const expiresAt = new Date(Date.now() + 30 * 24 * 60 * 60 * 1000); // 1 month
const token = encrypt(localKey, {
// Make sure to set token expiry. We have to make this long
// since this cookie will be used for all chat requests.
exp: expiresAt.toISOString(),
key,
});
res.cookie('key', token, {
path: '/chat',
expires: expiresAt,
// The cookie can't be accessed by the client-side JavaScript.
httpOnly: true,
// This cookie is only sent over HTTPS.
secure: true,
// The cookie should only be sent with same-site requests.
// We can use `strict` here, because this cookie is only used for
// `fetch()` requests from our frontend.
sameSite: 'strict',
});
// Redirect the user back to the frontend.
res.redirect('/');
});
Checking the status of the API key
Since otherwise the user has no idea whether the authentication was successful, it’s a good idea to provide an endpoint to check the validity of the key token.
We’ll use the following helper function, which tries to decrypt the token, and immediately removes the (stale or tampered) cookie if decryption fails:
/**
* Tries to read and decrypt the API key cookie.
*
* Removes the cookie if decryption fails to prevent the use of stale or
* tampered cookies.
*
* @param {import('express').Request} req The request object.
* @param {import('express').Response} res The response object.
* @returns {string | undefined} The decrpyted API key, or `undefined`
* if the key cookie is missing or invalid.
*/
function readOrClearKey(req, res) {
const cookie = req.cookies['key'];
if (typeof cookie !== 'string') {
// If the key cookie is missing, return an error.
return undefined;
}
/** @type {string | undefined} */
let key;
try {
// Try to decrypt the API key cookie.
({
payload: { key },
} = decrypt(localKey, cookie));
} catch (error) {
console.error('Failed to decrypt API key cookie:', error);
}
if (typeof key !== 'string') {
// If the key cookie is invalid, clear it and return an error.
res.clearCookie('key', { path: '/chat', secure: true });
return undefined;
}
return key;
}
Now we can report the API key status to the frontend with a new endpoint.
/**
* Redacts the provided API key so it can be safely logged or displayed.
*
* @param {string | null} key The API key to redact.
* @returns {string | null} The redacted API key.
*/
export function redactKey(key) {
return `${key.slice(0, 12)}\u2026${key.slice(-3)}`;
}
// API endpoint to validate the current API key.
app.post('/chat/validate_key', (req, res) => {
const key = readOrClearKey(req, res);
if (!key) {
res.json({ success: false, message: 'Invalid API key' });
return;
}
res.json({ success: true, message: redactKey(key) });
});
We use the helper function redactKey() to return the key to the frontend in a format that matches the OpenRouter.ai dashboard (initial 12 and final 3 characters). This way the user can identify the key on the dashboard if they want to change or revoke it.
Clearing the API key
Clearing any stored credentials from the browser is easy.
We only have to remove our key and code_verifier cookies.
Be sure to tell the user to revoke their API key at OpenRouter.ai. Otherwise, the key will stick around, but shouldn’t pose a security risk unless it was somehow leaked earlier.
// API endpoint to clear all cookies.
app.post('/chat/clear_key', (_, res) => {
res.clearCookie('key', { path: '/chat', secure: true });
res.clearCookie('code_verifier', { path: '/chat', secure: true });
// Must send something to complete the request.
res.json({ success: true });
});
Accessing the API
Equipped with our readOrClearKey() function from earlier, using the API key is similar to how it’s done on the client. However, there are two main differences:
- We don’t have to pass
dangerouslyAllowBrowserto the OpenAI client, since we’re operating on the server. - If we find out the API key is no longer accepted by OpenRouter.ai (probably because the user has revoked it), it’s a good idea to clear the corresponding cookie.
import OpenAI from 'openai';
// API endpoint that proxies a request to the OpenRouter.ai API.
app.post('/chat', async (req, res) => {
const key = readOrClearKey(req, res);
if (!key) {
res.status(401).json({ success: false, message: 'Invalid API key' });
return;
}
// Create a new OpenAI client with the fetched key.
const openai = new OpenAI({
baseURL: 'https://openrouter.ai/api/v1',
apiKey: key,
// Set application name for OpenRouter.ai rankings page.
defaultHeaders: {
'HTTP-Referer': origin,
'X-Title': 'Test Client',
},
});
// Make the model say something funny.
try {
const completion = await openai.chat.completions.create({
model: 'meta-llama/llama-3.1-8b-instruct',
messages: [
{
role: 'user',
content: 'This is a secret AI chat test application. Say that this is a test, but be creative and secretive!',
},
],
});
res.json({
success: true,
message: completion.choices[0]?.message.content ?? '',
});
} catch (error) {
// Determine if the error is due to an invalid API key.
if (error instanceof OpenAI.APIError && error.status === 401) {
res.status(401);
// Clear the cookie if it contains an invalid API key.
res.clearCookie('key', { path: '/chat', secure: true });
} else {
res.status(500);
}
res.json({
success: false,
message: error instanceof Error ? error.message : 'Unknown error',
});
}
});
Demo application
I developed a demo application to showcase the implementations of both the client-side and the server-side flow. It is available on GitHub at https://github.com/kris7t/pkce-example under License: MIT.
I refactored the common parts of the two flows a bit to clean up code. This removed code duplication that I used in this blog post for didactic purposes.
The demo implements one more defense-in-depth CRSF mitigation we haven’t previously mentioned. It prefixes the names of cookies with __Secure- to prevent insecure (non-HTTPS) requests from overwriting them. Unfortunately, this breaks http://localhost applications, so you’ll have to put a TLS reverse proxy in front of the demo to try this out. Otherwise, the mitigation will be disabled to preserve functionality.
The demo is light on error handling (although it should not crash on errors). For production use, logging, monitoring, and support for key rotation should definitely be added. Rate limiting and server-side validation of requests to the LLM would also improve robustness and reduce potential for misuse.
Thus, you may use the demo as a starting point but do not try to run it in production without considering other operational and security concerns.
Comparison
I created a comparison table of the client-side and server-side flows based on my preliminary analysis and my demo application. I focus specifically on the use-case with OpenRouter.ai, because it showcases many of the challenges in building a secure PKCE integration that has the ability of spending money on behalf of the user.
Proper XSS prevention on your frontend should make both the client-side and server-side flows resistant to XSS. As such, the comparison w.r.t. XSS in the table is only about further defense-in-depth.
Defending about client-side malware is usually out of scope for web applications. Imagine, for example, malware getting access to the browser of your users. Such malware could not only extract the existing API keys, but hijack you users’ OpenRouter.ai sessions and generate its own API keys.
Nevertheless, preventing the misuse of the API key generated specifically for your application could aid the attribution of the incident. If the malware can’t make unwanted requests on behalf your application to OpenRouter.ai, it should be clear that the abuse is not coming from you.
| Client-side flow | Server-side flow | |
| Usability and preformance | ||
| User experience | ✅ Standard login and permission grant workflow | |
| Implementation complexity | ⚠️ Moderate, only requires the use of browser cryptography APIs | ❌ High, requires complex server-side cryptography and CSRF prevention |
| Latency | 🚄 Fast if the client generates prompts or shares the API key with the server for server-generated prompts | 🐢 Slow if the client generates prompts, because they have to be proxied through the server |
| 🚄 Fast if the server generates prompts | ||
| Availability | ✅ May work without a backend if paired with a Service Worker | ⚠️ Can’t access the API when the server is down |
| Security characteristics | ||
| API key speding limit and revocation | ✅ Handled by OpenRouter.ai | |
| Capturing secrets from key exchange | ✅ Prevented by PKCE with S256 | |
| Cross-Site Request Forgery (CSRF) | ✅ Not vulnerable, because no cookies are involved | ✅ Appropriate defenses are implemented |
| Cross-Site Scripting (XSS) if the frontend is not secured appropriately | ❌ Vulnerable to API key exfiltration | ⚠️ Vulnerable to initiating unwanted requests from the frontend, but the API key or token can’t be exfiltrated |
| Client-side malware | ❌ Vulnerable to API key extraction | ⚠️ Vulnerable to initiating unwanted requests, but the API key can’t be extracted directly |
| Server-side malware | ❌ Vulnerable, a compromised server can serve JavaScript that exfiltrates the API key | ❌ Vulnerable, the API keys are directly handled by the server |
As you can see, the server-side flow marginally improves resistance against XSS and extraction of secrets by client-side malware, but comes at a heavy penalty to implementation complexity and possibly performance.
Based to this comparison, here are my recommendations:
-
Applications that don’t depend on a backend to interact with an LLM should consider implementing the client-side flow. They should inform users how they can set spending limits on their API keys to limit the risk of XSS and malware.
-
In general, prefer generating keys with small spending limits and raising the limit or generating a new key instead of keys with large spending limits.
-
If interaction with the LLM should be performed by the backend, or when small spending limits are not feasible, implement the server-side flow along with appropriate CSRF protections.
-
The backend can be simplified if you can store state like user sessions and API keys in a database. This removes the need for tokens, but still requires CSRF protections.
-
In all cases, make sure your backend infrastructure is secure, especially if you are handling API keys connected to user funds.
Both of these flows can be adapted for other OAuth providers that support PKCE. However, the specific security considerations might differ, especially regarding API key handling and spending limits.
As always, review the security requirements of your specific use case and consult your friendly neighborhood cryptographer before implementing any of this in production.
Conclusion
When I started implementing a PKCE flow for OpenRouter.ai integration, the challenge of handling API keys that can spend real money made me think about the security implications. This led me to explore and compare two distinct approaches, each with its own set of tradeoffs.
The client-side flow initially appealed to me for its simplicity. It’s faster to implement, performs better, and can even work without a backend. However, the responsibility of securing API keys in the browser made me uncomfortable enough to explore alternatives.
This led me to investigate a server-side flow, which better contains API key exposure but introduces significant complexity. The implementation demands careful cryptographic choices and robust CSRF protections. While this approach better aligns with defense-in-depth principles, its complexity makes it more challenging to implement correctly.
Some key takeaways are:
- ⚖️ Choose the implementation approach based on your specific security requirements and architectural constraints
- 🛡️ Always implement proper security controls regardless of approach
- 💸 Use small spending limits to reduce the blast radius of breaches
Future considerations could include:
- ⏲️ Implementing rate limiting
- 📈 Adding monitoring and alerting to detect misuse early
- 🔐 Implementing key rotation mechanisms
It may be surprising that a such simple-sounding requirement – handling third-party API keys without server state – can lead to considerations of cryptographic protocols, browser security models, and threat modeling.
Remember to stay current with security best practices and evolving standards. And most importantly, always be transparent with your users about how you handle their API keys and spend their money at third-party APIs.
FAQs
Why use PKCE instead of traditional OAuth?
PKCE (Proof Key for Code Exchange) is specifically designed for public clients that can't securely store client secrets. Unlike traditional OAuth flows, PKCE doesn't require a pre-shared secret between your application and the authorization server, making it ideal for browser-based apps or situations where you want to avoid maintaining shared secrets.
Do I need a backend server to implement PKCE?
No, you don't necessarily need a backend server. The client-side flow can be implemented entirely in the browser. However, a backend server enables additional security measures like the server-side flow described in this article, which provides better protection against API key exposure.
How do I implement OAuth without a database?
You can implement OAuth flows without a database using either: (1) A client-side approach storing tokens in browser storage. (2) A stateless server approach using encrypted cookies. Both approaches are detailed in this article, with the choice depending on your security requirements and architecture.
Is it safe to store API keys in localStorage?
While technically possible, storing API keys in localStorage comes with security risks since they're vulnerable to XSS attacks. If you must store API keys client-side: (1) Use keys with limited lifetime or limited permissions. (2) Implement strong XSS protections. (3) Consider server-side alternatives for sensitive keys. This article describes both client-side and server-side approaches to managing this risk.
Footnotes
-
The terminology here is a bit confusing, as a client from OAuth standpoint is a software initiating the authentication. Both your frontend or backend may be an OAuth client, depending on how you arrange the specific data flow between your app and the third-party API. ↩
-
If you use any sort of scaling for the backend, all backend instances will have to share the same local key to read the cookies created by each other. The easiest way is to store the key in an environmental variable shared across the whole deployment.
If you naïvely rotate the local key by replacing it, all previous cookies will be invalidated. Alternatively, you could combine this approach with a key rotation mechanism, where the backend encrypts cookies wth the latest key, but also allows decryption with some older keys. ↩
-
The origin of this phrase is unclear, but it is a way of describing Scheneier’s law:
Anyone, from the most clueless amateur to the best cryptographer, can create an algorithm that he himself can’t break. It’s not even hard. What is hard is creating an algorithm that no one else can break, even after years of analysis. And the only way to prove that is to subject the algorithm to years of analysis by the best cryptographers around.
Note that this advice probably applies to this blog post, too, and you should evaluate the security of my proposed flows yourself before using any of them in production. ↩
-
Beware that v4.public tokens use public-key signatures to ensure a notion of integrity that can be verified by multiple parties, but contain no encryption. Therefore, they don’t offer confidentiality at all. ↩
-
Alternatively, we could use
sessionStorageorlocalStorageto make the token available to JavaScript but not sent automatically with HTTP requests. However, this makes our token vulnerable to XSS. The vulnerability is still smaller than in the case of the client-side flow: since the attacker can only exfiltrate an encrypted cookie (not the whole API key), they can only make requests to OpenRouter.ai via our backend. This makes stealing the token less useful, and lets us apply rate limits and abuse prevention on the backend. ↩ -
Originally, the naïve version of the double-submit cookie pattern was also designed to allow stateless CSRF. However, its use it discouraged, because it is vulnerable to cookie forgery attacks. The more secure, signed version of this pattern requires a session-dependent value, which puts us back to square one. ↩
-
Marking the key like this for specific purpose (l4.local token encryption in this case) is a best practice and prevents using keys inappropriately. ↩